Contents:
Notes for the book.
Source code for the book.
Chapter 2: How the backpropogation algorithm works
Was introduced in the 70's, but came into light with this paper.
Today, it is the workhorse of learning in neural networks.
Warm up: a fast matrix-based approach to computing the output from a neural network
First, the notations,
For weights,
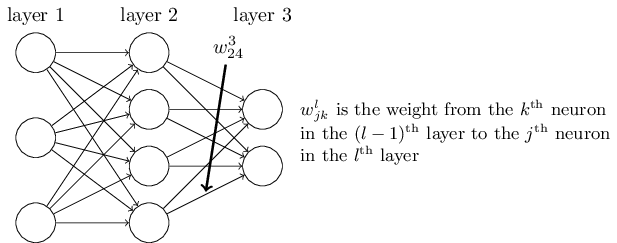
For biases and activations,
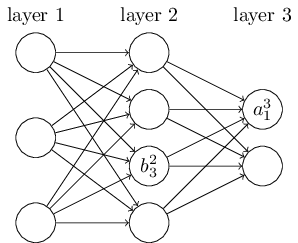
These are related,
which can be rewritten in vectorized form as,
This form is more compact and practical as we will be using libraries that provide fast matrix multiplication and vectorization capabilities.
The two assumptions we need about the cost function
The goal of backpropogation is to calculate the partial derivatives \(\partial C / \partial w\) and \(\partial C / \partial b\).
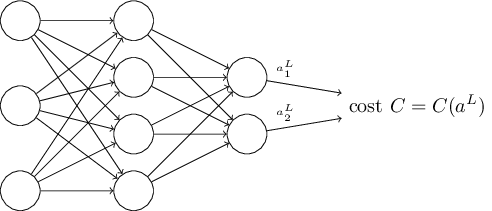
Here is an example of cost function we will be using(there can and will be others).
Now, the assumptions,
- The cost function can be written as an average \(C = \frac{1}{n} \sum_x C_x\) over cost \(C_x\) for individual training examples.
- The cost function can be written as a function of the outputs from the neural network:
The Hadamard product, \(s \odot t\)
\(s \odot t\) represents the elementwise product of two vectors.
The four fundamental equations behind backpropagation
First, we define the error in the \(j^{th}\) neuron in the \(l^{th}\) layer, \(\delta^l_j\)
An equation for the error in the output layer, \(\delta^L\):
Which can again be rewritten in vectorized form,
where, in case of a quadratic cost function, we have \(\nabla_a C = (a^L-y)\).So,
An equation for the error \(\delta^l\) in terms of the error in the next layer, \(\delta^{l+1}\):
Suppose we know the error \(\delta^{l+1}\) at the \(l+q^{\rm th}\) layer. When we apply the transpose weight matrix, \((w^{l+1})^T\), we can think intuitively of this as moving the error backward through the network, giving us some sort of measure of the error at the output of the \(l^{\rm th}\) layer.
By combining \((BP1)\) and \((BP2)\), we can compute the error \(\delta^l\) for any layer in the network.
An equation for the rate of change of the cost with respect to any bias in the network
which can also be written as,
An equation for the rate of change of the cost with respect to any weight in the network:
which can also be written as,
This can also be depicted as,
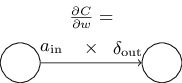
Looking at this image, we can also say that a weight will learn slowly if either the input neuron is low-activation, or if the output neuron has saturated, i.e. it's gradient has become too small(when its either high- or low-activation in case of sigmoid).
Summary of the four equations of backpropagation

Proof of the four fundamental equations
We start with the expression for \(\delta^L\)
Applying chain rule,
But, the output activation \(a_k^L\) of the \(k_{\rm th}\) neuron only depends on the weighted input \(x_j^L\) for the \(j^{\rm th}\) neuron when \(k=j\). And so, \(\partial a^L_k / \partial z^L_j\) vanishes when \(k \neq j\). So,
Recalling that, \(a^L_j = \sigma(z^L_j)\)
which is \((BP1)\) in component form.
Next, we prove \((BP2)\), which gives an equation for the error \(\delta^L\) in terms of the error in the next layer, \(\delta^{l+1}\).
Now,
Differentiating,
Substituting back in \((42)\),
which is \((BP2)\) in component form.
The backpropagation algorithm
- Input \(x\): Set the corresponding activation \(a^1\) for the input layer.
- Feedforward: For each \(l = 2, 3, \ldots, L\) compute \(z^l = w^la^{l−1} + b^l\) and \(a^l = \sigma(z^l)\).
- Output error \(\delta^L\): Compute the vector \(\delta^{L} = \nabla_a C \odot \sigma'(z^L)\).
- Backpropagate the error: For each \(l = L−1, L−2,\ldots, 2\) compute \(\delta^{l} = ((w^{l+1})^T \delta^{l+1}) \odot \sigma'(z^{l})\).
- Output: The gradient of the cost function is given by \(\frac{\partial C}{\partial w^l_{jk}} = a^{l-1}_k \delta^l_j\) and \(\frac{\partial C}{\partial b^l_j} = \delta^l_j\).
The above steps show backpropagation applied w.r.t. a single training example. In practice, it is common to use some a learning algorithm like stochastic gradient descent, computing the gradients of many training examples. In particular, the following algorithm applies gradient descent learning step, based on mini-batches.
- Input a set of training examples
- For each training example \(x\): Set the corresponding input activation \(a^{x,1}\) and perform the following steps:
- Feedforward: For each \(l = 2, 3, \ldots, L\) compute \(z^{x,l} = w^l a^{x,l-1}+b^l\) and \(a^{x,l} = \sigma(z^{x,l})\)
- Output error \(\delta^{x,L}\): Compute the vector \(\delta^{x,L} = \nabla_a C_x \odot \sigma'(z^{x,L})\).
- Backpropagate the error: For each \(l = L-1, L-2, \ldots, 2\) compute \(\delta^{x,l} = ((w^{l+1})^T \delta^{x,l+1}) \odot \sigma'(z^{x,l})\)
- Gradient descent: For each \(l = L, L-1, \ldots, 2\) update the weights according to the rule \(w^l \rightarrow w^l-\frac{\eta}{m} \sum_x \delta^{x,l} (a^{x,l-1})^T\), and biases according to the rule \(b^l \rightarrow b^l-\frac{\eta}{m} \sum_x \delta^{x,l}\).
Of course, in practice, we would also need an outer loop, generating the mini-batches, and another outer loop, stepping through the multiple epochs, but they are just ommitted for simplicity.
The code for backpropagation
The code for backpropagation was is contained in two methods, update_mini_batch, described in the last post, and backprop method, discussed here,
def backprop(self, x, y):
"""Return a tuple "(nabla_b, nabla_w)" representing the
gradient for the cost function C_x. "nabla_b" and
"nabla_w" are layer-by-layer lists of numpy arrays, similar
to "self.biases" and "self.weights"."""
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
# feedforward
activation = x
activations = [x] # list to store all the activations, layer by layer
zs = [] # list to store all the z vectors, layer by layer
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation)+b
zs.append(z)
activation = sigmoid(z)
activations.append(activation)
# backward pass
delta = self.cost_derivative(activations[-1], y) * \
sigmoid_prime(zs[-1])
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
# Note that the variable l in the loop below is used a little
# differently to the notation in Chapter 2 of the book. Here,
# l = 1 means the last layer of neurons, l = 2 is the
# second-last layer, and so on. It's a renumbering of the
# scheme in the book, used here to take advantage of the fact
# that Python can use negative indices in lists.
for l in xrange(2, self.num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-l+1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l-1].transpose())
return (nabla_b, nabla_w)
In what sense is backpropagation a fast algorithm?
Let's consider another approach, using numerical gradients,
Gradients for the biases can be computed similarly.
This looks promising. It's conceptually simple and easy to implement.
Certainly much more promising than the chain rule to compute the gradient!
However, turns out it is extremely slow. That's because for each distinct weight \(w_j\) we need to compute \(C(w+\epsilon e_j)\) in order to compute \(\delta C/\delta w_j\).
That means, if we have a million weights, to compute the gradient, we need to calculate the cost a million different times, requiring a million forward passes through the network.
Backpropagation enables us to simultaneously calculate all the partial derivatives using just one single forward pass through the network, followed by one backward pass. Which is roughly the same as just two forward passes through the network. And so even though backpropagation appears superficially complex, it is much, much faster.
But even that speedup was not enough in the early days, and we need some more clever ideas to make deeper networks work.
Backpropagation: the big picture
So, we have seen what backprop does, and the steps that it takes. But does that give an intuitive idea of how it does what it does?
To improve our intuition,
let's imagine that we've made a small change \(\Delta{w_{jk}^l}\) to some weight in the network.
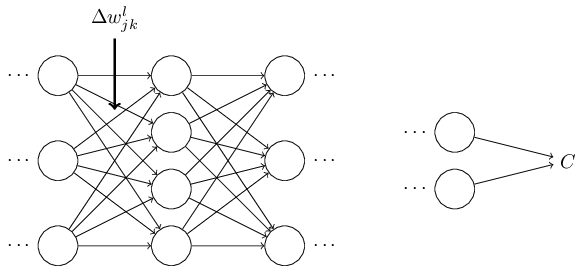
That will cause a change in its output activation,
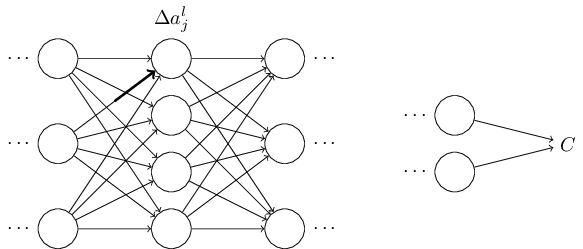
which will cause a change in all the activations in the next layer.
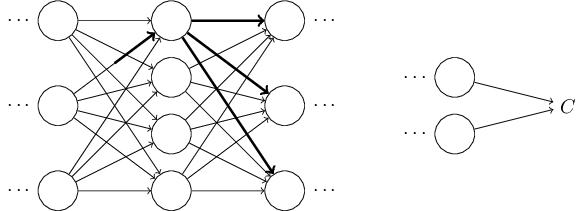
and it would propagate to the final cost function.
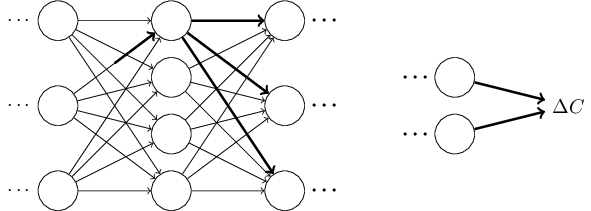
This change can also be written mathematically as,
This suggests if we propagate the change \(\Delta w^l_{jk}\) forward, we should be able to compute \(\delta{C}/\delta w^l_{jk}\).
Let's try that out,
The change \(\Delta w^l_{jk}\) causes a small change \(\Delta a_l_j\) in the activation of the \(j^{th}\) neuron in the \(l^{th}\) layer.
This will cause change in all the activations in the next layer. We'll concentrate on just a single such activation.
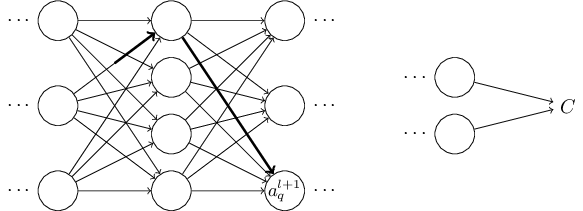
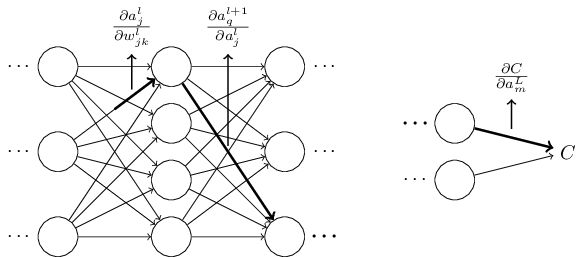
Which can be written as,
Substituting in \((48)\),
And, following similar patterns, it propagates to the change in final cost \(\Delta C\).
Comments
comments powered by Disqus